Hoe we een berichtenplatform naar miljoenen events per maand schaalden
Een praktische blik op event sourcing, CQRS, read models, AI-workers en saaie infrastructuur voor een platform dat grote hoeveelheden WhatsApp-berichten verwerkt.
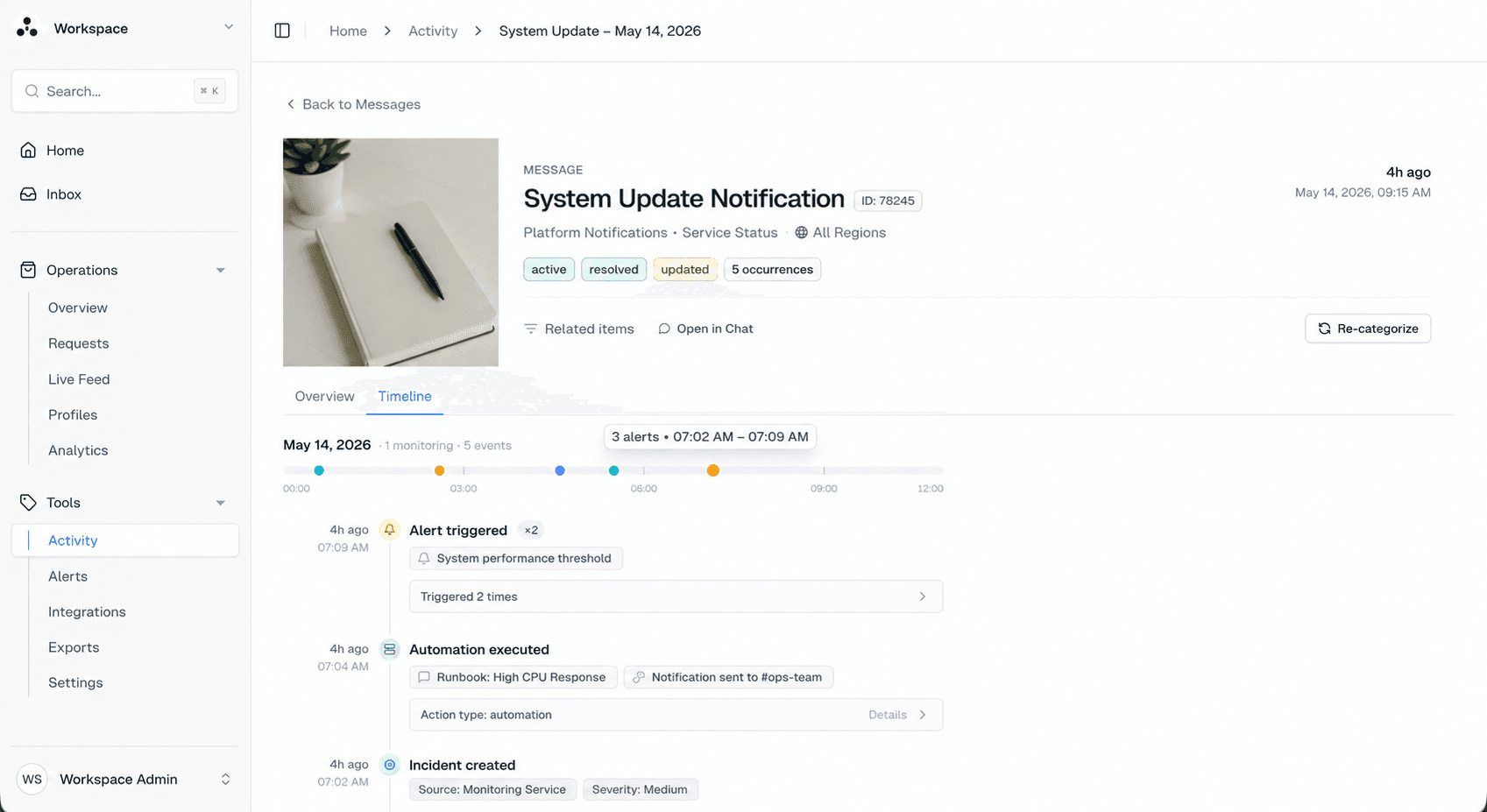
De afgelopen twee weken hebben we de backend en frontend opnieuw neergezet voor een platform dat grote hoeveelheden WhatsApp-berichten verwerkt.
Niet een paar meldingen per dag, maar honderdduizenden berichten per maand en een historische dataset met miljoenen events.
De uitdaging was niet alleen technisch. De echte vraag was:
Hoe bouw je een systeem dat snel blijft, fouten kan herstellen, AI slim gebruikt, maar niet afhankelijk wordt van AI? En hoe zorg je dat het begrijpelijk blijft voor een klein team dat snel ontwikkelt?
Dit is hoe we dat hebben aangepakt.
Het probleem
De eerste versie werkte in het begin prima. Maar naarmate het volume groeide, begon het systeem op de verkeerde plekken pijn te doen.
De webhook die berichten binnenkreeg, deed te veel tegelijk. Berichten ontvangen, media verwerken, classificeren, tabellen bijwerken en data klaarzetten voor de frontend zaten te dicht op elkaar.
Daardoor kon één traag onderdeel invloed hebben op de rest. Een externe API die langzaam reageerde, kon de ingest vertragen. Een fout in AI-classificatie kon doorwerken in de schermen. Een zware query kon voelen alsof “de hele backend traag” was, terwijl eigenlijk één afgeleide tabel verkeerd werd opgebouwd.
Daar komt bij dat WhatsApp-data rommelig is. Berichten kunnen dubbel binnenkomen, worden aangepast of verwijderd, in meerdere groepen verschijnen of later pas media bevatten. Ook oude data moet opnieuw geïmporteerd kunnen worden zonder live verkeer te verstoren.
Als je dat allemaal direct in producttabellen schrijft, eindig je met een systeem waarin niemand meer precies weet waarom een bepaalde rij bestaat.
De fix: eerst feiten, daarna meningen
De belangrijkste keuze was simpel:
Eerst vastleggen wat er is gebeurd. Daarna pas bepalen wat het betekent.
Dat is event sourcing in simpele taal.
In plaats van alleen de huidige stand van zaken te bewaren, slaan we gebeurtenissen op. Bijvoorbeeld:
- webhook ontvangen
- bericht gezien
- bericht aangepast
- media gevonden
- classificatie afgerond
- alert aangemaakt
Die gebeurtenissen zijn feiten. Ze worden niet overschreven. Als later blijkt dat een scherm of tabel fout is opgebouwd, kunnen we die opnieuw maken op basis van de oorspronkelijke gebeurtenissen.
De database wordt daarmee een soort tijdlijn van alles wat er is gebeurd.
De applicatie leest die tijdlijn niet rechtstreeks voor elk scherm. Dat zou te traag worden. Daarom gebruiken we projectors: kleine processen die events lezen en daar snelle tabellen van maken voor de frontend.
Dus:
- De ingest schrijft events.
- Workers verwerken zware taken.
- Projectors bouwen snelle leestabellen.
- De API leest uit die snelle tabellen.
- En alles is opnieuw op te bouwen.
CQRS zonder religie
We hebben ook CQRS toegepast, maar praktisch gehouden.
CQRS betekent dat je schrijven en lezen uit elkaar haalt.
Aan de schrijfkant heb je acties zoals: “selecteer deze groep”, “maak deze alert”, “verstuur dit bericht” of “corrigeer deze classificatie”. Die acties schrijven nieuwe events.
Aan de leeskant heb je vragen zoals: “toon mijn berichten”, “toon listings”, “toon alerts” of “toon profielstatistieken”. Die lezen uit snelle tabellen die speciaal voor de frontend zijn gemaakt.
Dat voorkomt dat één database-model alles tegelijk moet kunnen. Schrijven draait om betrouwbaarheid. Lezen draait om snelheid en gebruiksgemak.
Daar hadden we geen groot framework voor nodig. Gewoon duidelijke services, Postgres-tabellen, handlers, projectors en migraties.
Waarom we van Supabase-runtime naar gewone Postgres gingen
Supabase was nuttig in de eerdere fase, maar voor deze schaal wilden we minder magie en meer controle.
De nieuwe runtime draait op PostgreSQL 16 op een dedicated Hetzner-server. De applicatie praat via een private setup met de database. Geen publieke databasepoort, geen onnodige lagen ertussen.
Dat klinkt misschien minder hip, maar voor dit soort volume is dat precies wat je wilt:
voorspelbare performance, controle over indexes, duidelijke query plans, standaard Postgres tooling en genoeg ruimte voor miljoenen events en read-model-rijen.
De grootste winst was mentaal: de database werd weer een saaie, betrouwbare basislaag. Snelheid kwam niet uit een extra tool, maar uit goede tabellen, goede indexes en meetbare queries.
Ingest moest saai en snel worden
De webhook doet nu zo min mogelijk.
Hij valideert de secret, leest de payload, checkt of het bericht niet al eerder is verwerkt, schrijft een event weg en geeft snel antwoord terug.
Wat hij bewust niet doet:
- geen AI-call
- geen media downloaden
- geen zware contact-sync
- geen marktstatistieken bijwerken
- geen frontend-schermen direct voeden
Dat is belangrijk. De webhook is de voordeur. Die moet altijd open blijven.
Alles wat traag, extern of foutgevoelig is, gaat naar workers.
De kracht van read models met AI-coding
Het product draait op read models: snelle tabellen voor berichten, aanbiedingen, profielen, alerts, dashboards en timelines.
Die tabellen zijn geoptimaliseerd voor de frontend. Soms staat data daarin dubbel. Soms zijn er extra helper-tabellen voor zoeken, groepslidmaatschappen, telefoonprefixen of statistieken.
Dat is geen probleem, want de bron van waarheid blijft de event store.
Als een read model fout is, fixen we de projector en bouwen we de tabel opnieuw op.
Juist met AI-coding is dat belangrijk. AI kan snel code maken, maar je architectuur moet herstelbaar zijn als een aanname niet klopt. Fouten zijn niet erg, zolang het systeem erop gebouwd is om ze netjes te herstellen.
AI is een worker, geen fundament
AI speelt een belangrijke rol in het product, maar zit niet in de kritieke route.
Eerst moet een bericht betrouwbaar binnenkomen. Pas daarna mag AI er iets van vinden.
Classificatie draait via workers, met retries, timeouts en duidelijke events voor resultaten. De AI-output is dus niet “de waarheid”, maar een afgeleid resultaat.
Als het model beter wordt, prompts veranderen of gebruikers correcties doen, kunnen we opnieuw classificeren en nieuwe events toevoegen.
Zo blijft AI waardevol, zonder dat het fundament ervan afhankelijk wordt.
Frontend v2: eerlijk over verwerkingstijd
De frontend moest aansluiten op deze manier van werken.
Een actie zegt niet altijd: “alles is klaar”. Soms zegt het systeem: “ontvangen, we verwerken dit nu”.
De UI kan dan rustig laten zien dat iets wordt bijgewerkt, en daarna automatisch de nieuwste data ophalen zodra de projecties zijn verwerkt.
Schermen zijn opgebouwd rond duidelijke onderdelen: bericht, listing, contact, alert, sessie en groep. Elk detail heeft teruglinks naar de bron. Zo kun je altijd zien waarom iets bestaat.
Dat is extra belangrijk in een systeem met AI. Als AI iets concludeert, moet je kunnen terugklikken naar de onderliggende data.
Hoe we dit in twee weken konden doen
De snelheid kwam niet doordat we “gewoon veel AI” gebruikten.
De snelheid kwam doordat de regels helder waren.
Vooraf stonden de principes vast:
- ingest eerst, AI later.
- Commands schrijven events.
- Queries lezen read models.
- Projectors zijn opnieuw draaibaar.
- Zware berekeningen zitten niet in de hot path.
- Migraties zijn veilig en stapsgewijs.
- Monitoring hoort bij het systeem, niet pas achteraf.
Daarna kon AI helpen met de uitvoering: handlers, tests, migraties, frontend-components, API-types, runbooks en performance reports.
De architectuur gaf de rails. AI hielp om sneller over die rails te bewegen.
In twee weken is daardoor een groot deel van het platform verschoven van “alles hangt aan elkaar” naar een event-driven systeem met een dedicated database, losse workers, replay tooling, monitoring, workspace-auth, frontend v2-schermen en meetbare performance.
Wat we leerden
Schaalbaarheid begint niet bij Kubernetes, queues of een grotere server.
Het begint bij eigenaarschap over tijd.
- Kun je uitleggen wat er is gebeurd?
- Kun je een fout herstellen?
- Kun je een read model opnieuw bouwen?
- Kun je live verkeer blijven accepteren terwijl je oude data importeert?
- Kun je AI tijdelijk uitzetten zonder dat ingest stopt?
Als het antwoord ja is, heb je een schaalbaar systeem.
De tweede les: saaie infrastructuur is vaak sneller. Eén goede Postgres-database, duidelijke indexes, private networking, goede metrics en kleine processen brengen je verrassend ver.
De derde les: AI maakt softwareontwikkeling sneller, maar alleen als de codebase duidelijke grenzen heeft. Zonder grenzen maakt AI vooral sneller meer chaos. Met duidelijke events, read models, idempotency en goede documentatie kun je AI juist veilig laten versnellen.